Earlier this month I taught a two-day workshop on growth curve analysis at Georg-Elias-Müller Institute for Psychology in Göttingen, Germany. The purpose of the workshop was to provide a hands-on introduction to using GCA to analyze longitudinal or time course data, with a particular focus on eye-tracking data. All of the materials for the workshop are now available online (http://dmirman.github.io/GCA2018.html), including slides, examples, exercises, and exercise solutions. In addition to standard packages (ggplot2, lme4, etc.), we used my psy811 package for example data sets and helper functions.
Showing posts with label ggplot2. Show all posts
Showing posts with label ggplot2. Show all posts
Friday, March 23, 2018
Monday, April 20, 2015
Plotting Factor Analysis Results
A recent factor analysis project (as discussed previously here, here, and here) gave me an opportunity to experiment with some different ways of visualizing highly multidimensional data sets. Factor analysis results are often presented in tables of factor loadings, which are good when you want the numerical details, but bad when you want to convey larger-scale patterns – loadings of 0.91 and 0.19 look similar in a table but very different in a graph. The detailed code is posted on RPubs because embedding the code, output, and figures in a webpage is much, much easier using RStudio's markdown functions. That version shows how to get these example data and how to format them correctly for these plots. Here I will just post the key plot commands and figures those commands produce.
Wednesday, August 13, 2014
Plotting mixed-effects model results with effects package
As separate by-subjects and by-items analyses have been replaced by mixed-effects models with crossed random effects of subjects and items, I've often found myself wondering about the best way to plot data. The simple-minded means and SE from trial-level data will be inaccurate because they won't take the nesting into account. If I compute subject means and plot those with by-subject SE, then I'm plotting something different from what I analyzed, which is not always terrible, but definitely not ideal. It seems intuitive that the condition means and SE's are computable from the model's parameter estimates, but that computation is not trivial, particularly when you're dealing with interactions. Or, rather, that computation was not trivial until I discovered the effects package.
Friday, April 4, 2014
Flip the script, or, the joys of coord_flip()
Has this ever happened to you?

I hate it when the labels on the x-axis overlap, but this can be hard to avoid. I can stretch the figure out, but then the data become farther apart and the space where I want to put the figure (either in a talk or a paper) may not accommodate that. I've never liked turning the labels diagonally, so recently I've started using coord_flip() to switch the x- and y-axes:
ggplot(chickwts, aes(feed, weight)) + stat_summary(fun.data=mean_se, geom="pointrange") + coord_flip()

It took a little getting used to, but I think this works well. It's especially good for factor analyses (where you have many labeled items):
library(psych)
pc <- principal(Harman74.cor$cov, 4, rotate="varimax")
loadings <- as.data.frame(pc$loadings[, 1:ncol(pc$loadings)])
loadings$Test <- rownames(loadings)
ggplot(loadings, aes(Test, RC1)) + geom_bar() + coord_flip() + theme_bw(base_size=10)

library(lme4)
m <- lmer(weight ~ Time * Diet + (Time | Chick), data=ChickWeight, REML=F)
coefs <- as.data.frame(coef(summary(m)))
colnames(coefs) <- c("Estimate", "SE", "tval")
coefs$Label <- rownames(coefs)
ggplot(coefs, aes(Label, Estimate)) + geom_pointrange(aes(ymin = Estimate - SE, ymax = Estimate + SE)) + geom_hline(yintercept=0) + coord_flip() + theme_bw(base_size=10)

Thursday, April 4, 2013
R 3.0 released; ggplot2 stat_summary bug fixed!
The new version of R was released yesterday. As I understand it, the numbering change to 3.0 represents the recognition that R had evolved enough to justify a new number rather than the addition of many new features. There are some important new features, but I am not sure they will affect me very much.
For me, the much bigger change occurred in the update of the ggplot2 package to version 0.9.3.1, which actually happened about a month ago, but I somehow missed it. This update is a big deal for me because it fixes a very unfortunate bug from version 0.9.3 that broke one of my favorite features: stat_summary(). As I mentioned in my previous post, one of the great features of ggplot is that allows you to compute summary statistics "on the fly". The bug had broken this feature for certain kinds of summary statistics computed using stat_summary(). A workaround was developed relatively quickly, which I think is a nice example of open-source software development working well, but it's great to have it fixed in the packaged version.
For me, the much bigger change occurred in the update of the ggplot2 package to version 0.9.3.1, which actually happened about a month ago, but I somehow missed it. This update is a big deal for me because it fixes a very unfortunate bug from version 0.9.3 that broke one of my favorite features: stat_summary(). As I mentioned in my previous post, one of the great features of ggplot is that allows you to compute summary statistics "on the fly". The bug had broken this feature for certain kinds of summary statistics computed using stat_summary(). A workaround was developed relatively quickly, which I think is a nice example of open-source software development working well, but it's great to have it fixed in the packaged version.
Saturday, March 2, 2013
Why I use ggplot
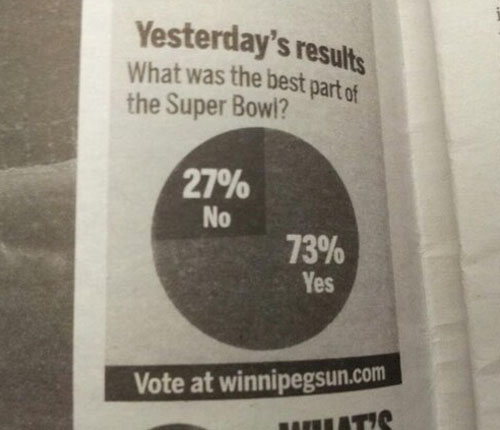
(via Flowing Data)
For the last few years I have been using the ggplot2 package to make all of my figures. I had used Matlab previously and ggplot takes some getting used to, so this was not an easy switch for me. Joe Fruehwald's Penn R work group was a huge help (and more recently, he posted this excellent tutorial). Now that I've got the hang of it, there are two features of ggplot that I absolutely can't live without.
Tuesday, August 7, 2012
Customizing ggplot graphs
There are many things I love about the R package ggplot2. For the most part, they fall into two categories:
- The "grammar of graphics" approach builds a hierarchical relationship between the data and the graphic, which creates a consistent, intuitive (once you learn it), and easy-to-manipulate system for statistical visualization. Briefly, the user defines a set of mappings ("aesthetics", in the parlance of ggplot) between variables in the data and graph properties (e.g., x = variable1, y = variable2, color = variable3, ...) and the visual realizations of those mappings (points, lines, bars, etc.), then ggplot does the rest. This is great, especially for exploratory graphing, because I can visualize the data in lots of different ways with just minor edits to the aesthetics.
- Summary statistics can be computed "on the fly". So I don't need to pre-compute sample means and standard errors, I can just tell ggplot that this is what I want to see and it will compute them for me. And if something doesn't look right, I can easily visualize individual participant data, or I can look at sample means excluding some outliers, etc. All without creating separate copies of the data tailored to each graph.
This great functionality comes at a price: customizing graphs can be hard. In addition to the ggplot documentation, the R Cookbook is a great resource (their section on legends saved me today) and StackOverflow is a fantastic Q&A site. Today I also stumbled onto a very detailed page showing how to generate the kinds graphs that are typical for psychology and neuroscience papers. These are quite far from the ggplot defaults and my hat is off to the author for figuring all this out and sharing it with the web.
Subscribe to:
Posts (Atom)